DataFrame Merge에 대해서 알아보자
DataFrame을 병합한다는 것은 말그대로 두개의 각기 다른 테이블을 하나로 합친다는 것이다.
Database의 join과 같은 개념이다. Database의 행과 열로 구성된 table 이란 이름이 case와 변수로 구성된 DataFrame으로 변했을 뿐이다. 데이터를 공부하시는 분들이라면 DataFrame용어로 접할 일이 많을 것이다.
Merge에 대한 여러 방법이 있는데 대표적인 세 가지만 한번 알아보자.
1. Inner Join
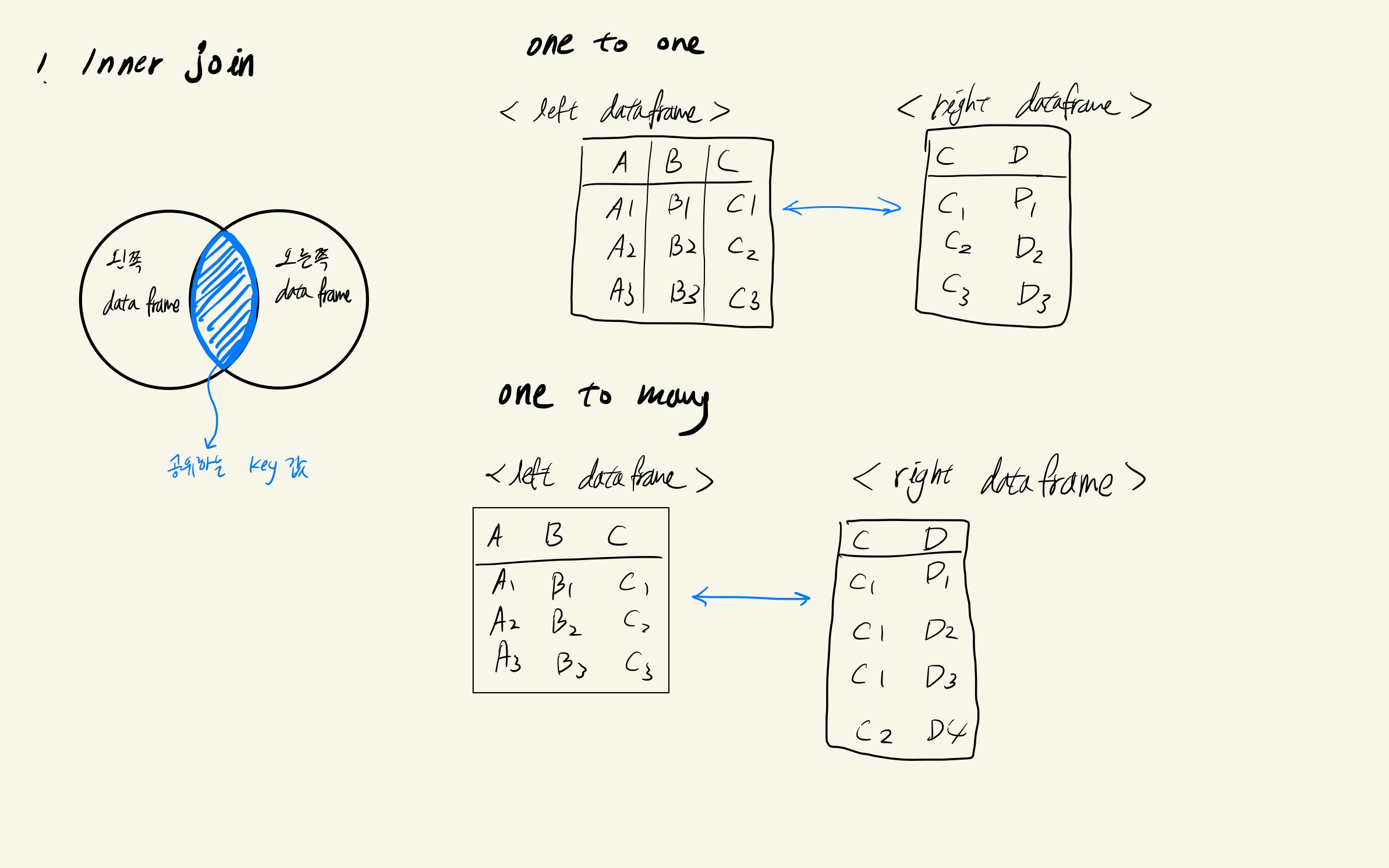
inner join은 합치고자 하는 두 개의 테이블(DataFrame)에 있는 공유하고 있는 값을 기반으로 합치는 것을 말한다. 때문에 일치하지 않는 key값이 있다면, 결과 테이블로 포함되지 않는다.
코드를 통해 알아보자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
import numpy as np
import pandas as pd
data1 = {
'학번': [1, 2, 3, 4],
'이름': ['아이유', '김연아', '홍길동', '강감찬'],
'학과': ['철학', '경영', '컴퓨터', '물리']
}
data2 = {
'학번': [1, 2, 4, 5],
'학년': [2, 4, 3, 1],
'학점': [1.5, 2.0, 4.1, 3.8]
}
df1 = pd.DataFrame(data1) # 테이블 1
df2 = pd.DataFrame(data2) # 테이블 2
display(df1)
"""
학번 이름 학과
0 1 아이유 철학
1 2 김연아 경영
2 3 홍길동 컴퓨터
3 4 강감찬 물리
"""
display(df2)
"""
학번 학년 학점
0 1 2 1.5
1 2 4 2.0
2 4 3 4.1
3 5 1 3.8
"""
# 두개의 테이블을 보면 학번을 공유하고 있다.
# 학번을 key 값으로 설정하여 테이블을 합쳐보자.
# merge (inner join -- 일치되는 것끼리 합침. 위 Venn Diagram 참조)
df3 = pd.merge(df1, df2, on='학번', how='inner')
# 첫번째 인자 (df1)이 left table이 되며
# 두번째 인자 (df2)가 right table이 된다.
# 어떤걸 기준으로 합치세요~ 알려주는 게 'on'을 갖고 알려줌.
display(df3)
"""
학번 이름 학과 학년 학점
0 1 아이유 철학 2 1.5
1 2 김연아 경영 4 2.0
2 4 강감찬 물리 3 4.1
"""
# df1 이 먼저 나왔으니, df1 컬럼이 우선적으로 나옴
# 'inner join'이니깐, 학번이 겹치는 정보들만 나옴.
# 홍길동 같은 경우엔 df1에 학번 3으로 있는데, 학번3은 df2에 없음. 그래서 자동으로 빠졌다.
# 5번 학번을 갖고 있는 친구 경우엔, df1에 정보가 없음. 공통된게 없기 때문에 역시 빠졌다.
Inner join의 다른 예를 하나 더 훑어보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
data1 = {
'학번': [1, 2, 3, 4],
'이름': ['아이유', '김연아', '홍길동', '강감찬'],
'학과': ['철학', '경영', '컴퓨터', '물리']
}
data2 = {
'학번': [1, 2, 4, 1], ### 여기 학번을 5에서 1로 바꿈. 좀 말은 안되지만 예제로 해보자
'학년': [2, 4, 3, 1],
'학점': [1.5, 2.0, 4.1, 3.8]
}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df3 = pd.merge(df1, df2, on='학번', how='inner')
display(df3)
# 출력해서 테이블을 본다면, 1번 학번을 가진 학생 아이유가 두 번 등장하는 걸 볼 수 있다.
# 있는거 다 연결하는구나? 1:1연결이 아니구나?
"""
학번 이름 학과 학년 학점
0 1 아이유 철학 2 1.5
1 1 아이유 철학 1 3.8
2 2 김연아 경영 4 2.0
3 4 강감찬 물리 3 4.1
"""
2. Outer Join
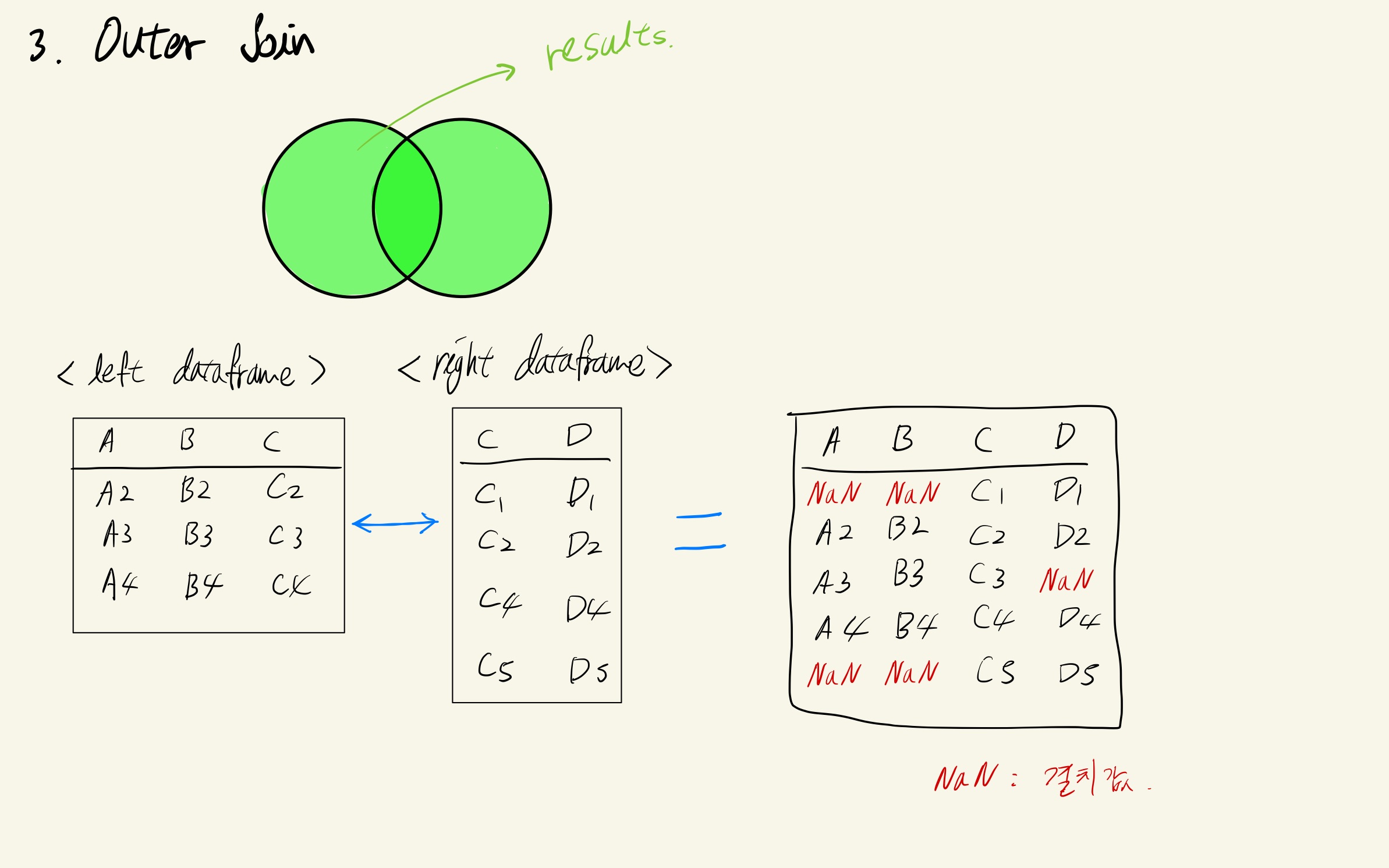
바로 예제를 살펴보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 첫 예제와 같은 데이터를 사용.
import numpy as np
import pandas as pd
data1 = {
'학번': [1, 2, 3, 4],
'이름': ['아이유', '김연아', '홍길동', '강감찬'],
'학과': ['철학', '경영', '컴퓨터', '물리']
}
data2 = {
'학번': [1, 2, 4, 5],
'학년': [2, 4, 3, 1],
'학점': [1.5, 2.0, 4.1, 3.8]
}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df3 = pd.merge(df1, df2, on='학번', how='outer')
display(df3)
# outer join은 다 합친다.
# 서로 연결점이 없어도 결과에 다 포함시키는게 full outer join임.
# 대신 접점이 없는 값들은 결치값 (NaN)이 생성됨!
"""
학번 이름 학과 학년 학점
0 1 아이유 철학 2.0 1.5
1 2 김연아 경영 4.0 2.0
2 3 홍길동 컴퓨터 NaN NaN
3 4 강감찬 물리 3.0 4.1
4 5 NaN NaN 1.0 3.8
"""
첫 예제였던 inner join 같은 경우에는 양쪽 테이블에서 같이 공유하는 키(학번)가 1, 2, 4번이었기에 학번 3과 학번 5의 데이터는 삭제가 된 채 결과 테이블을 받았다.
outer join 은 위 Venn Diagram에서 볼 수 있듯이 모든 데이터를 테이블로 가져온다.
3. Left Join
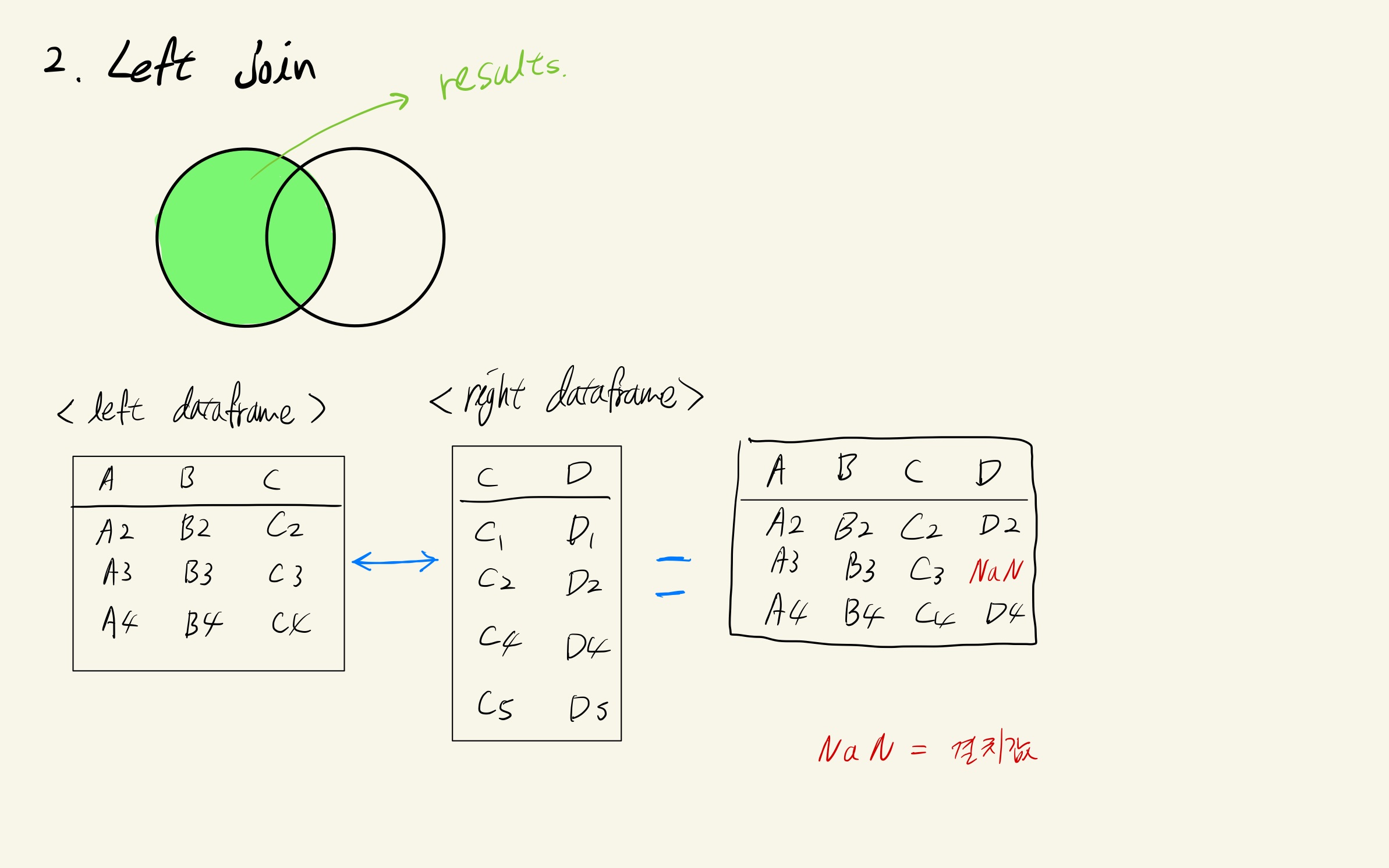
세번째로 다룰 케이스는 Left join이란 친구다.
outer join의 변형이라고 생각하면 쉽다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 마찬가지로 같은 데이터 셋을 활용
import numpy as np
import pandas as pd
data1 = {
'학번': [1, 2, 3, 4],
'이름': ['아이유', '김연아', '홍길동', '강감찬'],
'학과': ['철학', '경영', '컴퓨터', '물리']
}
data2 = {
'학번': [1, 2, 4, 5],
'학년': [2, 4, 3, 1],
'학점': [1.5, 2.0, 4.1, 3.8]
}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 왼쪽에 있는것만 포함시킴 여기선 df1
df3 = pd.merge(df1, df2, on='학번', how='left')
display(df3)
"""
학번 이름 학과 학년 학점
0 1 아이유 철학 2.0 1.5
1 2 김연아 경영 4.0 2.0
2 3 홍길동 컴퓨터 NaN NaN
3 4 강감찬 물리 3.0 4.1
"""
이렇게 왼쪽 데이터프레임에 있는 데이터에 기초해서 dataframe을 병합하였다.
오른쪽 데이터프레임에선 학번 3에 관한 정보가 없기에, 학년과 학점 컬럼에선 결치값(NaN)으로 결괏값이 나왔다.
(Right join 또한 같은 메커니즘이기에 추가적인 설명은 하지 않겠다.)
4. Merge 하고자 하는 DataFrame의 Key이름이 다른 경우
나중에 논문을 위한 어떤 가계패널데이터를 사용한다거나, cps데이터를 통한 연구를 한다면 굉장히 빈번하게 당면하는 문제중 하나가 데이터들간의 `key이름이 다른 경우이다. 이럴 땐 어떻게 하는가? 간단하다.
위에서 사용했던 코드를 그대로 사용하되, on=이라는 인자 대신에 left_on 그리고 right_on을 사용해주면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
data1 = {
'학번': [1, 2, 3, 4],
'이름': ['아이유', '김연아', '홍길동', '강감찬'],
'학과': ['철학', '경영', '컴퓨터', '물리']
}
data2 = {
'학생학번': [1, 2, 4, 5],
'학년': [2, 4, 3, 1],
'학점': [1.5, 2.0, 4.1, 3.8]
}
###### 학생학번은 학번과 같은 의미를 가짐 ######
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 첫번째 인자로 들어온 dataframe의 키를 left_on에 대입
# 두번째 인자로 들어온 dataframe의 키를 right_on에 대입.
df3 = pd.merge(df1, df2, left_on='학번', right_on='학생학번', how='inner')
display(df3)
"""
학번 이름 학과 학생학번 학년 학점
0 1 아이유 철학 1 2 1.5
1 2 김연아 경영 2 4 2.0
2 4 강감찬 물리 4 3 4.1
"""
다만 기존의 inner join과 다른점은 학생학번이라는 컬럼이 추가되었을 뿐이다.
다양한 경우에서 접할 수 있다.
“여기서 궁금한건 그럼 언제 inner join을, outer join을 또 left or right join을 사용하느냐?”
문제에 따라 다르다!
데이터를 보면서 결치값은 어떻게 되고, 데이터프레임 구조는 어떻게 되는지 보면서 직접 핸들링해보면서 정하는 수 밖엔 없다.
그 안에서 논리적인 방법을 찾고 데이터 핸들링을 하면 된다. (말은 쉽지만 굉장히 어렵죠 :))