음.. 사실 pandas를 정리해보면서 든 생각중 하나는 DataFrame의 세계나 활용도가 너무 광범위해서 하나를 설명할 때 데이터를 불러오는 방법에 대해서 순서에 맞게끔 단계별로 기록하는게 정말 힘들다.
그냥 pandas 함수나 좀 기록하세욧!!
뭐 사실 이렇게 하는것도 하나의 방법이 될 수 있다고 생각하지만, 이해를 해가며 공부하기에는 적합하지 않을 수 있다는게 필자의 생각이다.
포스팅의 순서나 이런 내용 외적인 부분에 관해서는 계속해서 수정을 통해 다시 한 번 정렬하며 더 나은 방법을 찾아 정리를 해보겠다.
서두가 길었다!
우선 csv 파일을 DataFrame으로 불러와서 json으로 변환해보자!
🐼: csv to json
1
2
3
4
5
6
7
8
9
10
11
12
import numpy as np
import pandas as pd
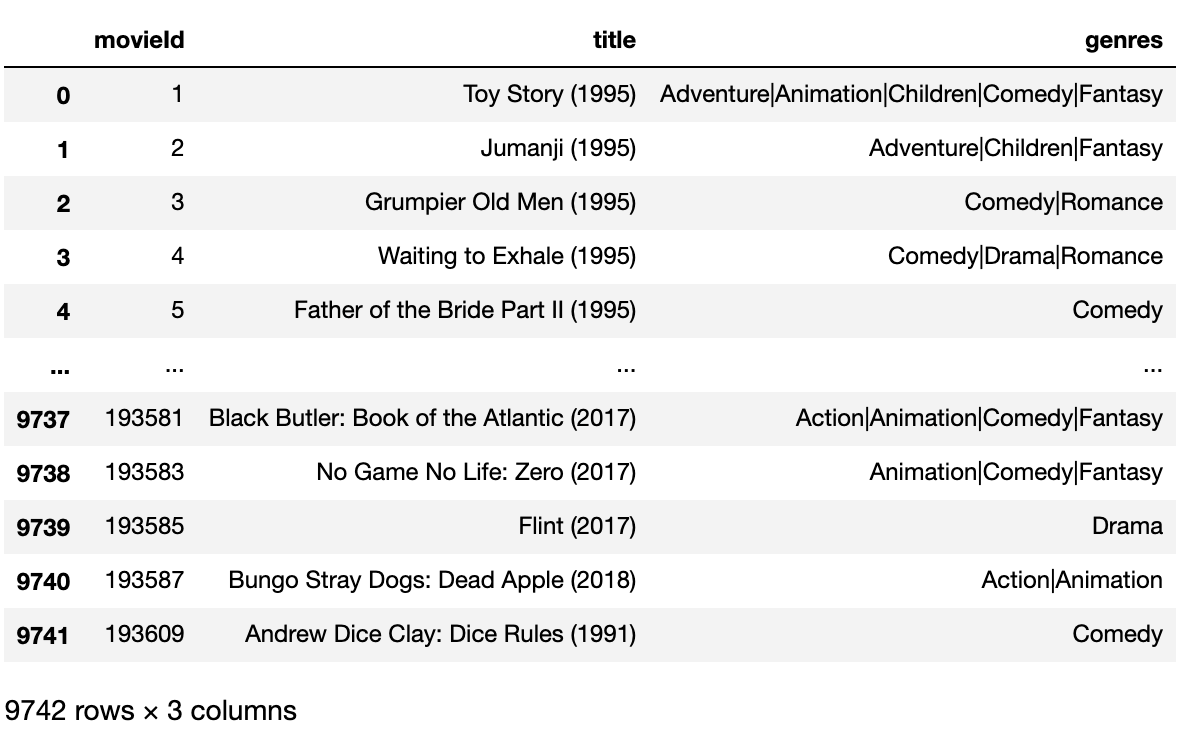
df = pd.read_csv('./data/movie/movies.csv')
# 필자의 로컬디스크에 저장되어있는 csv파일 경로이다.
display(df) # 아래 screenshot 을 보시길..
# 자 이제 아래와 같은 코드를 통해 .json 파일로 변경해주자.
with open('./data/csv_to_json.json', 'w', encoding='utf-8') as f:
df.to_json(f, force_ascii=False, orient='columns')
막간을 이용해 with 에 대해 간단하게 설명해보자면.. with 이란 명령어는 리소스를 꽉!!! 잡고 있는거다. file 처리를 하려면 :
- file을 열어야하고 (open)
- file에 내용을 작성하고
- file을 닫아야 한다. 그래서 늘
file open그리고file close가 같이 나와야한다. 근데with구문이 나오면file close처리는 따로 해주지 않아도 된다..
사람마다 스타일이 다르겠지만, 필자는 늘 with 구문으로 처리를 하는 편이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
with open('./data/csv_to_json.json', 'w', encoding='utf-8') as f:
# 여기서 경로에 관해 얘기를 하자면
# 가장 앞에 나온 .은 지금 현재 위치를 말함
# 지금 내가 있는 곳에서 / data 라는 디렉토리안에
# csv_to_json.json 이란 걸로
# 'w': write, 즉 쓰다. 파일을 작성해줘! 이소리임
# 그래서 그런 이름을 가진 파일이 없다면, 새롭게 파일을 만든다.
# 반대로 읽기만 하는 기능을 가진 명령어는 'r'임을 기억하자.
df.to_json(f, force_ascii=False, orient='columns')
# dataframe이 갖고 있는 to_json 이라는 함수가 있음.
# 현재 pandas dataframe인 df를 to_json 제이슨으로 변경해줘! 이거임.
# 어떤 파일을 변경해? aliasing을 잡은 f라는 파일
# 그게 ./data/csv_to_json.json 이 놈이 되는거다.
# force_ascii는 False로 잡아야하고, (한글 특성상)
# orient는 columns로 하겠다고 선언한거다.
# orient default는 columns임.
# 이제 json data가 생성되고 orient에 의해 column 명이 json의 key값이 됨
와우 복잡하네요. pandas 궁금해서 검색하다가 별 쓸데 없는거 보고 가네요.. 이렇게 느끼실 거 같다.
하지만 dict와 조화를 굉장히 잘 이루는 dataframe 특성상 dict와 비슷한 json 또한 친해질 필요가 있다.

컬럼이 많고 뭐가 값이 좀 많아서 징그럽긴한데 저렇게 생긴 친구가 json이다.
적은 데이터를 갖고 있는 json을 보면 와 뭐야 dict 아니야? 싶을 정도로 유사하게 생겼고 그만큼 불러오기도 쉽다.
음 말 나온김에 dict 을 이용해서 json을 직접 만들어보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import numpy as np
import pandas as pd
import json
data = {'name': ['아이유', '김연아', '홍길동'],
'dept': ['CS', 'Math', 'Mgmt'],
'age': [25, 29, 30]}
# key 값이 dataframe의 column이 되는거임
# value의 개수가 행의 수가 되는거임
df = pd.DataFrame(data) # 위 dictionary를 데이터프레임으로 변환!
# 출력물:
"""
name dept age
0 아이유 CS 25
1 김연아 Math 29
2 홍길동 Mgmt 30
"""
# 아까처럼 df를 json 파일로 저장해보자.
# open 안에 경로와 만들 파일명을 정해주고 orient 값을 주면 됨.
with open('./data/student_json_column.json', 'w', encoding='utf-8') as f:
df.to_json(f, force_ascii=False, orient='columns')
# force_ascii 는 아스키를 강제 시킬거니? 라고 묻는거임. utf-8을 쓴다면 false로 표기.
# orient에서 columns 값은 원래 디폴트임.
# to_json() 함수는 dataframe을 json으로 바꾸는 메서드임.
# 그래서 어떤 파일의 종류든, csv뿐만아니라 데이터프레임으로 불러올 수 있다면 다 json
# 으로 변경이 가능함. 왜냐면 데이터프레임을 json으로 바꾸는 것이기에.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 이렇게 json이 나타난다.
{
"name":{
"0":"아이유",
"1":"김연아",
"2":"홍길동"
},
"dept":{
"0":"CS",
"1":"Math",
"2":"Mgmt"
},
"age":{
"0":25,
"1":29,
"2":30
}
}
굉장히 dict 와 유사하게 생기지 않았는가?
key값 있고, value값 있고…. 음???? 그런데 ` orient=’columns’로 설정을 했더니 처음 json key-value pair에서 key값으로 column명이 들어왔고, 그에 상응하는 value값으로 또 다른 json`이 들어왔다. 그 안에 인덱스 번호를 갖고 키와 밸류의 형태로 나타난 걸 알 수 있다.
음… 전형적인 json 구조이긴 하나, 조금 복잡해졌다.
다른 방법은 없을까? 그럴땐 orient=record 를 사용하면 다른 형태로 json에 저장할 수 있다.
1
2
3
4
with open('./data/student_json_record.json', 'w', encoding='utf-8') as f:
df.to_json(f, force_ascii=False, orient='records')
# orient 가 records임
# records 는 행이라는 뜻을 가짐 (a.k.a row, observation)
자 orient 값을 변경해서 저장하였다. json 을 한번 살펴보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
[
{
"name":"아이유",
"dept":"CS",
"age":25
},
{
"name":"김연아",
"dept":"Math",
"age":29
},
{
"name":"홍길동",
"dept":"Mgmt",
"age":30
}
]
// 이번엔 전체를 json 배열로 잡았음.
// 첫번째 json은 이름은 아이유, 학과는 컴싸, 나이는 25
// 두번째 json은 이름은 김연아, 학과는 수학, 나이는 29
// 세번째 json은 이름은 홍길동, 학과는 경영, 나이는 30
// 한줄 한줄 한줄이 json으로 떨어져서 사용하기 용이한 감이 있다.
이번에는 python list형태로 요소가 json인 것으로 저장되었다. 때에 따라 편리한 기능을 줄 수 있으리라 생각된다.
또 다른 방식이 있을까?
1
2
3
# orient = 'values'
with open('./data/student_json_value.json', 'w', encoding='utf-8') as f:
df.to_json(f, force_ascii=False, orient='values')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
[
[
"아이유",
"CS",
25
],
[
"김연아",
"Math",
29
],
[
"홍길동",
"Mgmt",
30
]
]
이렇게 중첩리스트가 사용되어 기록된 것을 볼 수 있다.
이거 프로그래밍 적으로 편하게 처리할 수 있다는 장점이 있음. 물론 때에 따라 다름.
🐼: 영화진흥위원회 Open API 데이터 불러오기
우선 Open API를 사용하려면 허가를 받아야한다. 받지 않았다면, 한국영화진흥위원회에 들어가서 회원가입후 필요한 키를 받아오자.
(참고로 이 포스팅은 어느정도 open api를 다룰줄 안다는 가정하에 작성하였다.)
프론트엔드에 경험이 있으신 분들이라면 api 뭐 jQuery로 불러와서 작업을 처리하는것에 익숙해져 있을 수도 있다고 생각한다.
우린 그냥 파이썬에서 프로그래밍적으로 urllib 이라는 라이브러리를 사용해서 불러올 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
############ 1. 필요한 module 부터 import 하자
import numpy as np
import pandas as pd
import json
import urllib
# 서버 쪽에 request 를 보내야함. httprequest 라이브러리를 통해서 해야함 >> urllib
# 맨땅에서는 못함. ajax는 그자체가 html, jquery, javascript 였음.
############ 2. 영화진흥위원회 Open API를 호출하기를 위한 url이 있어야함
movie_url = 'http://www.kobis.or.kr/kobisopenapi/webservice/rest/boxoffice/searchDailyBoxOfficeList.json'
# key 값과 targetDt 는 들어가야함. 이 api의 필수 조건임.
query_string = '?key=<여기는 키값입니다>&targetDt=20210801'
# ?key= '발급받은 키값을 넣어주자'
# & 으로 이어서
# targetDt 까지 값을 줘야지 호출이 되는 구조이다.
# 모든 open api가 그런건 아님. 보통은 설명서에 나와있다!
# 그래서 url을 합쳐준다면...
last_url = movie_url + query_string
# 이 Url을 이용해서 서버프로그램을 호출해보자.
result_obj = urllib.request.urlopen(last_url)
# request를 보내면 나한테 뭐가 와?
# response가 오지
# 그 response안에는 여러가지 데이터가 옴. json을 포함해서
print(result_obj)
# 출력물:
# <http.client.HTTPResponse object at 0x7f8c4140c050>
# 이렇게 객체가 나온다면 호출 성공임!
# 오케이 2번 완료 3번으로 넘어가자
########### 3. 가져온 json 데이터를 dictionary로 바꿔주자
# 결과 객체를 가져왔잖아. 결과 객체 안에 있는 결과 데이터(json)를 읽어야함.
result_json = result_obj.read()
result_dict = json.loads(result_json)
# json 데이터를 읽어라! 이런 함수임
# json을 dict로 바꾸는 함수
print(result_dict)
# 출력물:
# {'boxOfficeResult': {'boxofficeType': '일별 박스오피스', 'showRange': '20210801~20210801',
# 'dailyBoxOfficeList': [{'rnum': '1', 'rank': '1', 'rankInten': '0', 'rankOldAndNew': 'OLD', 'movieCd':
# '20204117', 'movieNm': '모가디슈', 'openDt': '2021-07-28', 'salesAmt': '2434875350', 'salesShare': '59.7',
# 'salesInten': '284051980', 'salesChange': '13.2', 'salesAcc': '7521988780', 'audiCnt': '241879',
# 'audiInten': '30906', 'audiChange': '14.6', 'audiAcc': '788292', 'scrnCnt': '1688', 'showCnt': '7209'},
# ........
# 이렇게 딕셔너리를 얻었는데, 구조가 되게 애매함.
# 이걸 적절하게 내가 사용할 수 있도록 어떻게 데이터프레임을 만들것인가...
# 2차원 형태의 행과 열이 있는 데이터 프레임으로 만들거야.
# 그런데 뭐가 막 많아 2차원으로 어떻게 바꿔줄 수 있을까?
# 어떻게 만들까??
# 내가 원하는 DataFrame의 형태!
# 이걸 api 호출에 성공하면 이걸 최우선적으로 생각해야함.
# (순위) (제목) (판매액)
# rank title saleAmt
# 1 랑종 '49559450'
# 2 은혼 더 파이널 '9303340'
# 이런식으로 만들어야함.
# df = pd.DataFrame({
# 'rank': [1, 2, 3, 4...],
# 'title': ['랑종', '은혼 더 파이널', ...]
# 'salesAmt': ['49559450', '9303340', ... ]
# }) 이런식으로 만들면 되지 않을까 싶다
# 그럼 우리가 갖고 있는 딕셔너리 안에서 저걸 뽑아내면 됨.
# 어떻게 할까?
rank_list = [] # 빈 리스트를 만들자
title_list = []
sales_list = []
for tmp in result_dict['boxOfficeResult']['dailyBoxOfficeList']:
rank_list.append(tmp['rank'])
title_list.append(tmp['movieNm'])
sales_list.append(tmp['salesAmt'])
# 프린트문으로 list가 잘만들어졌는지 확인해보고
print(rank_list)
print(title_list)
print(sales_list)
# 이상 없으면 데이터 프레임으로 만들어주자.
df = pd.DataFrame({
'rank': rank_list,
'title': title_list,
'salesAmt': sales_list
})
display(df)
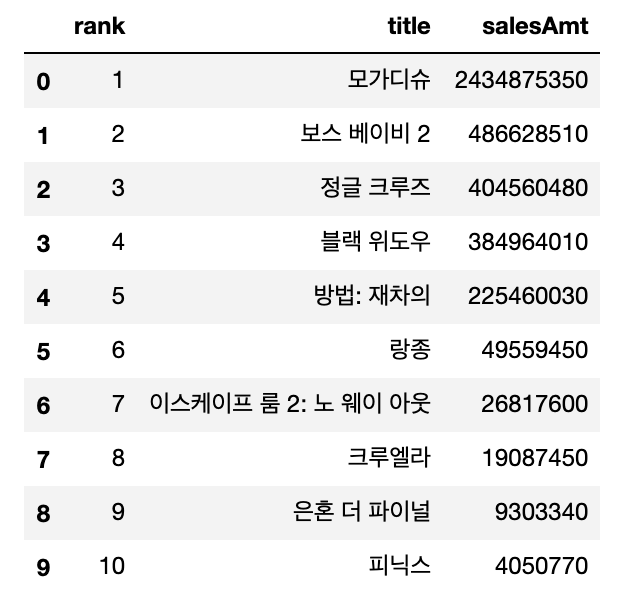
이렇게 Open API를 예쁜 data frame으로 출력해보았다.
다음 몇개의 포스팅은 이렇게 얻은 데이터를 갖고 적절한 데이터 핸들링으로 데이터를 정제한 뒤 집계함수를 이용한 EDA 를 하는 일련의 과정에 대해서 소개하려고 한다.
지금은 여기까지.
끄읏트. 👋