Multiple Linear Regression Using TensorFlow
지난 포스팅에서 단일 변수를 갖고 sklearn 라이브러리와 기본 파이썬을 이용해서 선형회귀분석을 해보았다(링크).
이번 포스팅에선 독립 변수 두개를 더 추가해서 총 3개의 독립변수를 갖고 진행해보도록 하자.
\[\hat{y} = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_3\]그리고 이젠 tensorflow라이브러리도 같이 활용을 할 예정이니 참고하길 바란다.
기본적인 데이터 구성을 살펴보자면…
| x1 | x2 | x3 | t |
|---|---|---|---|
| 30 | 70 | 90 | 180 |
| 70 | 80 | 70 | 177 |
| 90 | 100 | 80 | 198 |
| 30 | 50 | 20 | 105 |
이렇게 네개의 변수로 training data set이 구성되어 있다.
x1, x2, x3는 독립변수, t는 종속변수를 나타낸다.
이렇게 생긴 데이터 셋을 갖고 회귀분석을 하게 된다면 다중회귀분석을 하게 되는거다.
바로 예제로 들어가보자.
1
2
3
4
5
6
7
8
9
# 필요 패키지 로딩
# set environment
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
from scipy import stats # zscore
from sklearn import linear_model # sklearn으로도 모델 생성, 학습, 예측
from sklearn.preprocessing import MinMaxScaler # normalisation
데이터 로딩 및 이상치 결치 처리를 위한 코드:
( ozone.csv 파일은 추후 깃헙에 올려두겠다. (링크) )
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# Raw Data Loading
df = pd.read_csv('./data/ozone/ozone.csv', sep=',')
training_data_set = df[['Solar.R', 'Wind', 'Temp', 'Ozone']]
# 1. 결치값 처리
training_data = training_data_set.dropna(how='any') # NaN행 삭제
# display(training_data.shape) # (111, 4)
# 2. 이상치 처리
zscore_threshold = 1.8
outlier = training_data['Ozone'][ np.abs(stats.zscore(training_data['Ozone'])) > zscore_threshold ]
training_data = training_data.loc[ ~training_data['Ozone'].isin(outlier), :] # 103 rows × 2 columns
# 3. 정규화 처리
# scaling 작업을 수행하는 객체를 하나 생성 (입력값 처리 하는놈 1개, label 처리 하는 놈 1개)
scaler_x = MinMaxScaler()
scaler_y = MinMaxScaler()
scaler_x.fit(training_data.iloc[:, :-1].values) # training_data.loc[:, 'Solar.R':'Temp'].values
# 각각 x에 대한 스케일러가 다 필요한게 아님.
# x전체에 대한 하나의 scaler면 충분함 (n x 3) 행렬로 처리하기때문.
scaler_y.fit(training_data['Ozone'].values.reshape(-1,1))
training_data.iloc[:, :-1] = scaler_x.transform(training_data.iloc[:, :-1].values)
# training data set의 x의 값들을 정규화된 값으로 채워 넣는 코드임
training_data['Ozone'] = scaler_y.transform(training_data['Ozone'].values.reshape(-1,1))
# 마찬가지로 label을 정규화된 값으로 채워 넣는 코드.
display(training_data) # 이렇게 dataframe을 출력해보면 값들이 0~1사이로 떨어진걸 볼 수 있다.
# 4. Training Data Set
x_data = training_data.iloc[:, :-1].values
t_data = training_data['Ozone'].values.reshape(-1, 1)
이제 tensorflow로 그래프를 그리고 실행시켜보자.
training data set을 받아들이는 node 만들자.
- 데이터를 받기 위한 코드가 필요하다 =>
tf.placeholder
- 데이터를 받기 위한 코드가 필요하다 =>
Weight (
W) and Bias (b) 를 매번 바꿔주어야함. 그리고 최초W와b는 난수이다.- 매번 바꾸기 위해서 node를 변수로 잡자 ->
tf.Variable() - 난수 설정을 위해
tf.random.normal()이라는 메서드를 이용
- 매번 바꾸기 위해서 node를 변수로 잡자 ->
결국 우리가 사용하고자 하는 회귀 식은 $ \hat{y} = w_1x_1 + w_2x_2 + w_3x_3 + b $ 이다.
이걸 행렬곱으로 표현해보면, $ \hat{y} = XW + b $ 이렇게 된다.
이걸
tensorflow로 표현해보면:H = tf.matmul(X, W) + b이런 식으로 표현이되는 이게 우리가 사용할 모델이다.지난번 파이썬으로 구현했을때와 마찬가지로
loss function설정, 학습을 이용한W,b업데이트, 그리고tensorflow만의 그래프를 실행시키는session설정 및 실행, 마지막으로 반복학습을 해주면 된다.
코드를 통해 해보자!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
######### 1. 실제 독립변수 (X) 와 종속변수 (T) 를 추가하기 위한 node 생성
X = tf.placeholder(shape=[None,3], dtype=tf.float32)
# 컬럼의 개수는 고정. 들어오는 행의 개수는 상관하지 않는다.
# -1 의 의미를 가진 None 이란 keyword를 사용.
# None의 뜻은 없다가 아님. don't care임. 마음대로 넣어라 임.
# 즉 "row는 주는대로 받겠다." 이소리임
T = tf.placeholder(shape=[None,1], dtype=tf.float32)
######### 2. W and b 설정
W = tf.Variable(tf.random.normal([3,1]), name='weight')
# 나중에 값을 바꿀 수 있는 텐서플로우만의 변수.
# 독립 변수(X)의 열의 크기와 W행의 크기가 같아야함.
# 이름은 굳이 안줘도 됨. 하지만 저렇게 이름을 주면 저 이름으로 사용가능.
# tf.random 텐서플로가 갖고 있는 랜덤중에서도 normal이라는 정규분포 속성을 이용.
# np.random과 똑같음
b = tf.Variable(tf.random.normal([1]), name='bias')
######### 3. hypothesis 설정
H = tf.matmul(X, W) + b
######### 4. loss function 설정
loss = tf.reduce_mean(tf_square(H-T))
# H - T (예측 데이터 - 실제 데이터) 제곱. 그리고 그거에 대한 평균값
######### 5. Gradient Descent Algorithm을 통한 학습으로 W, b 재설정
train = tf.train.GradientDescentOptimizer(learning_rate=1e-4).minimize(loss)
# 현재 W와 b에서 편미분을 통해 조금더 나아진 W와 b를 구하는 작업을 해주는 node임
# 러닝 레이트를 알려줘서 편미분해서 옵티마이즈 하라고 지시
# 또 뒤에 minimize(loss) 를 붙여주므로써 로스값을 최소화
######### 6. session & 초기화
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# Variable 사용시 초기화 함수가 꼭 나와야 작동을 한다.
######### 7. 학습노드를 이용하여 반복학습을 진행하자!
for step in range(300000):
tmp, loss_val = sess.run([train, loss], feed_dict={X: x_data, T: t_data})
# 노드를 실행하면 노드가 가진 값이 나옴. 그래서 tmp로 그 값을 배정
# 노드 두개를 실행. 각각 따로따로 실행하는거임.
# train 값은 중요한게 아님, W, b, loss 가 중요! 여기선 loss값만 나온다.
if step % 30000 == 0:
print("loss: {}".format(loss_val))
이걸 이제 실행을 시키면..!!!
1
2
3
4
5
6
7
8
9
10
loss: 2.0639138221740723
loss: 0.0571671687066555
loss: 0.04494921490550041
loss: 0.038130346685647964
loss: 0.03406700864434242
loss: 0.03147490695118904
loss: 0.029711879789829254
loss: 0.028445681557059288
loss: 0.0274963341653347
loss: 0.02676238864660263
이렇게 loss값이 최소화 되는 것을 볼 수 있다. 엄청 낮은 값은 아니지만.. 일단은 진행하자
자 이제 학습이 끝났다. 값을 예측해보자
1
2
3
4
5
6
7
8
9
10
11
12
# predict을 해보자.
# 이젠 Hypothesis를 실행해야함 => H node.
# H node를 실행하려면 X node의 placeholder에 값을 넣어줘야함.
predict_data = np.array([[180.0, 10.0, 80.0]]) # [Solar.R Wind Temp]
scaled_predict_data = scaler_x.transform(predict_data) # 값을 넣어줄때도 정규화 시켜서 넣어줘야함
scaled_result = sess.run(H, feed_dict={X: scaled_predict_data})
# placeholder에 값을 부여해서 실행!!
result = scaler_y.inverse_transform(scaled_result.reshape(-1,1))
# 정규화 된 값으로 결과가 튀어나오면 inverse_transform을 통해서 다시 스케일 업을 해주자.
print(result) # [[41.532608]]
[[41.532608]] 이렇게 결과가 나왔다.
참고로 sklearn에서는[[41.59545428]] 이라는 비슷한 결과가 나왔다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
### sklearn 으로 구현한 코드
# Raw Data Loading
df = pd.read_csv('./data/ozone/ozone.csv', sep=',')
training_data_set = df[['Solar.R', 'Wind', 'Temp', 'Ozone']]
# 1. 결치값 처리
training_data = training_data_set.dropna(how='any')
# display(training_data.shape) # (111, 4)
# 2. 이상치 처리
# 지대값은 우선 그냥 두자..
zscore_threshold = 1.8
outlier = training_data['Ozone'][ np.abs(stats.zscore(training_data['Ozone'])) > zscore_threshold ]
training_data = training_data.loc[ ~training_data['Ozone'].isin(outlier), :]
x_data = training_data.iloc[:, :-1].values
t_data = training_data['Ozone'].values.reshape(-1,1)
model = linear_model.LinearRegression()
model.fit(x_data, t_data)
sklearn_result = model.predict([[180.0, 10.0, 80.0]])
print(sklearn_result) # [[41.59545428]]
sklearn에서는 자체적으로 정규화를 하기때문에 따로 정규화 해서 데이터를 넘겨줄 필요가 없다.
이번 포스팅에선 Multiple Linear Regression에 대해서 배워보았다. 이 회귀분석 방법은 머신, 딥러닝의 기본이 된다. 잘 익혀두자.
마지막으로 tensorflow가 어떻게 작동하는지 알려주는 그림을 올리며, 따로 부가적인 설명 없이 포스팅을 마무리하겠다.
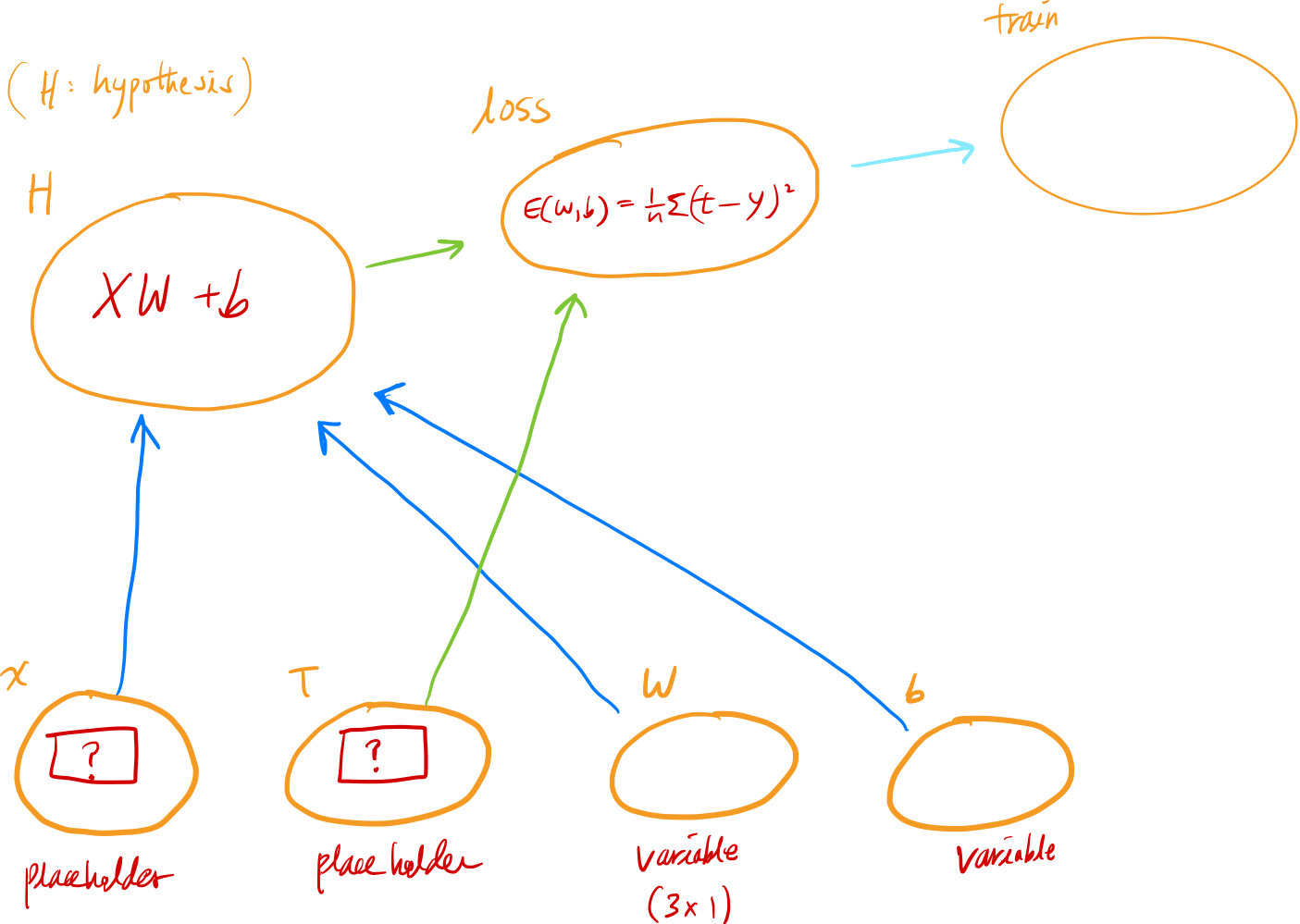
(중요한건 엣지의 포인팅 방향!)
오늘의 포스팅 끄읏트. 👋