sklearn을 이용한 Logistic Regression 예제
이번엔 위스콘신 대학에서 제공한 유방암 데이터셋을 이용하여 logistic을 구현해보자.
tensorflow로도 나름(?) 손쉽게 구현할 수 있으나, 이번엔 sklearn이 제공하는 데이터부터 메서드까지 한번 사용해보고자 한다.
sklearn의 k-fold cross validation이란 방식을 이용하면 원본 데이터셋을 train, validation으로 나눠서 작아지는 표본에 대한 단점을 보완할 수 있다. (엄밀히 말하면 holdout cross validation의 단점을 보완함)
(cross validation은 일반화 성능을 측정하기위해 데이터를 여러번 반복해서 나누어, 여러 모델을 학습하는 과정을 뜻함)
다만 문제는 시간이 4~5배 이상이 더 걸린다는건데 왜 그러느냐? 아래 그림을 보면 이해할 수 있다.
데이터를 폴드라고 부르는 비슷한 크기의 부분집합을 n개 만들어고, 각각 폴드의 정확도(accuracy)를 측정하여 검증을 진행한다.
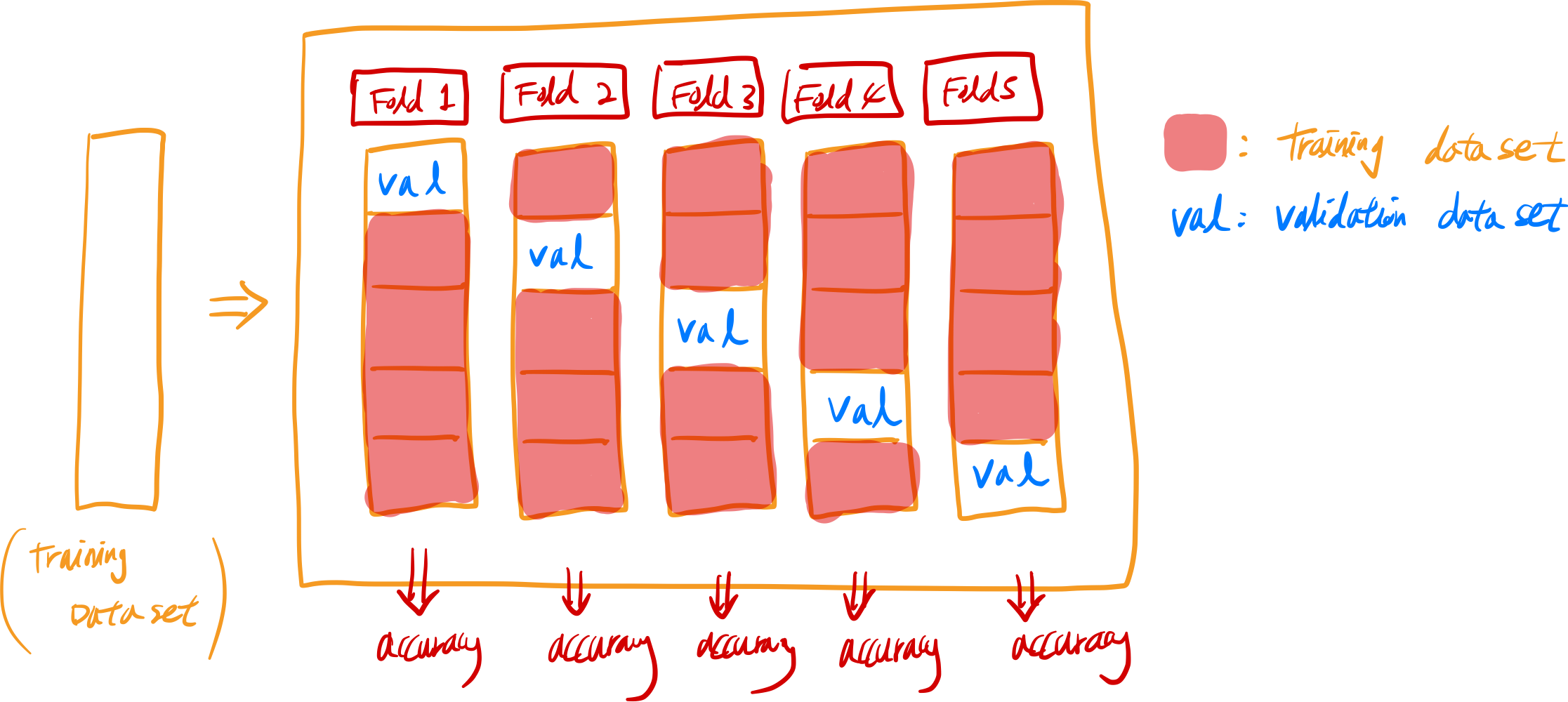
진행순서:
- 첫번째 폴드를 validation( or test ) data set으로 지정하고, 나머지 폴드를 training data set로 사용하여 학습한다
- 나머지 training data set으로 만들어진 세트의 정확도를 첫번째 폴드로 평가
- 다음은 두번째 폴드로 동일한 작업을 진행하고, 정확도도 두번째 폴드로 평가
- 이 과정을 마지막 폴드까지 계속 반복해서 진행
- 여기서 얻은 정확도들의 평균값이 k-fold 정확도가 된다.
서두가 길었다. 바로 예제로 들어가자
위스콘신 유방암 데이터는 워낙 유명한 예제라 쉽게 구할 수 있는 데이터 셋중에 하나이며, sklearn에서도 자체적으로 1차 가공된 데이터를 제공한다.
1
2
3
4
5
6
from sklearn.datasets import load_breast_cancer # 유방암 데이터에 대한 정보 로딩
import numpy as np
from sklearn.model_selection import train_test_split # train과 validation data를 분리해줌.
# hold-out cross validation
from sklearn import linear_model # logistic regression model
from sklearn.model_selection import cross_val_score # k-fold cross validation
Load Data
1
2
3
4
5
6
7
8
9
cancer = load_breast_cancer()
print(cancer) # dictionary 형태로 데이터가 쫘라라락 나옴. (진짜 딕셔너리는 아님)
x_data = cancer.data # shape: (569, 30)
t_data = cancer.target # shape: (569,)
# 프린트 문으로 데이터가 어떻게 생겨 먹은 놈들인지 한번씩 확인해보도록 하자.
print(x_data)
print(t_data)
cancer.DESCR을 입력하면 데이터 딕셔너리가 나오는데, 어떤 데이터를 갖고 있는지, 값들은 무엇을 의미하는지 출력물을 통해 확인하도록 하자.(본 포스팅에선 생략하였음..)
x_data 즉, feature는 총 30개가 있다. feature 개개인의 값들의 variation이 꽤 있는 것들이 있기때문에 정규화 작업을 해줘야하나 sklearn을 사용한다면 알아서 정규화까지 진행해주기 때문에 여기서는 넘어가도록 하자. 다만 tensorflow나 다른 패키지를 쓴다면 꼭 정규화를 해줄것.
자 우리는 ‘얼마나 좋은 모델인지’를 평가하기 위해서 정확도(accuracy)를 성능평가 지표(metric)로 사용할 예정이다. 그러려면 필수적으로 갖춰야하는 조건중 하나가 label의 값이 0, 1골고루 분포가 되어 있어야한다. 너무 한쪽으로 치우쳐져있다면, 정확도는 metric으로서 좋지 못한 선택이다.
레이블 값이 어떻게 분포 되어 있는지 한번 살펴보자.
1
2
print(np.unique(t_data, return_counts=True))
# (array([0, 1]), array([212, 357]))
0과 1의 값만 label로 들어가 있는 것을 볼 수 있으며 각각 212개 357개 있다. accuracy를 사용하기에 썩 좋은 분포는 아니나, 그래도 한번 사용해보겠다.
Training and Validation Dataset
1
2
3
4
5
6
7
8
9
train_x_data, valid_x_data, train_t_data, valid_t_data = \
train_test_split(x_data, t_data, test_size=0.2, stratify=t_data, random_state=1)
# x_data와 t_data를 분리
# test_size=0.2: validation dataset은 전체 데이터의 20%
# stratify=t_data: 그냥 막연하게 분리하지말고, 레이블에 있는 0과 1을 비율에 맞게 stratify해서 분리
# random_state=1: 무작위로 분리하되, random_state값을 1로 설정하면 같은 dataset이 나오게끔 설정
print(train_x_data.shape) # (455, 30)
print(valid_x_data.shape) # (114, 30)
이렇게 8:2 비율로 분리된 것을 볼 수 있다.
Model 설정
1
2
3
4
5
6
7
8
model = linear_model.LogisticRegression() # 로지스틱 객체
# k-fold cross validation (k-fold 교차검증)
score = cross_val_score(model, train_x_data, train_t_data, cv=5)
# model을 쓸거고, train_x_data와 train_t_data가 모델에 들어가서 사용된다.
# k-fold의 값은 cv를 통해 준다. => cv=5 => k=5. Thus, 5-fold
print(score) # [0.91208791 0.97802198 0.95604396 0.93406593 0.95604396]
[0.91208791 0.97802198 0.95604396 0.93406593 0.95604396] 이렇게 총 다섯개에 대한 값을 리턴받았다.
왜 다섯개냐고? k=5 즉 5-fold cross validation이니깐!
1
2
# 집계함수를 통해 값을 구하자.
print(score.mean()) # 0.9472527472527472
모델의 정확도는 약 94.7% 이다.
sklearn을 이용하면, 간단한 문제 같은 경우는 굉장히 쉽게 끝나는 것을 볼 수 있다.
아직까진 텐서플로우나 파이썬으로 노가다 하는 것보다 훨씬 효율적인 순간이 많은것은 사실인거 같다.
일단 이번 포스팅은 여기서 끄읏.
👋